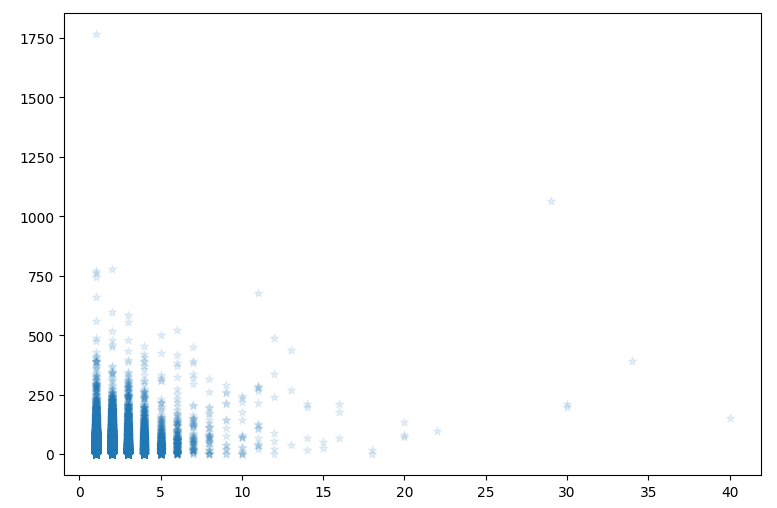
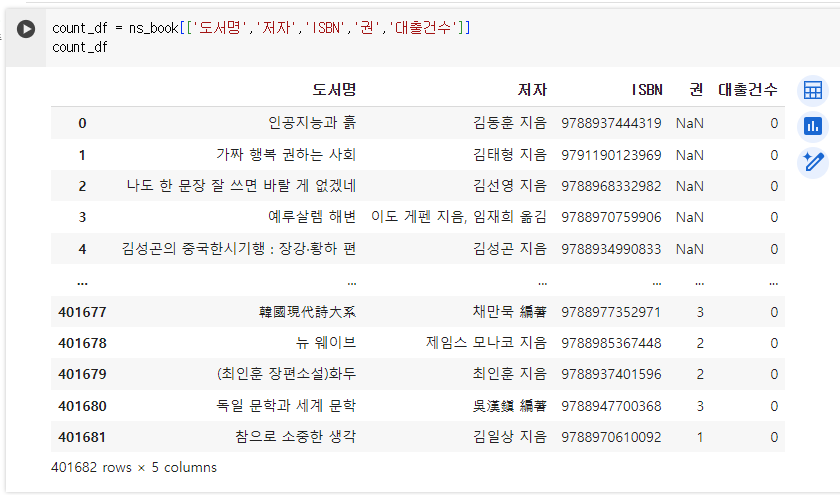
활용 도서 혼자 공부하는 데이터 분석 with 파이썬 : 네이버 도서 네이버 도서 상세정보를 제공합니다. search.shopping.naver.com plt.figure() 사용 방법 : plt.figure(figsize=(가로 사이즈, 세로 사이즈), dpi(해상도)=원하는 값) -> 그래프의 크기를 지정할 수 있다. 예제 코드 plt.figure(figsize=(9, 6)) # 그래프의 크기는 가로 9 , 세로 6으로 한다. plt.scatter(ns_book7['도서권수'], ns_book7['대출건수'], alpha=0.1) # x값은 ns_book7 데이터프레임의 "도서권수" 컬럼의 값들 # y값은 ns_book7 데이터프레임의 "대출건수" 컬럼의 값들 # 투명도는 0.1로 하고 # 산점도 그..